The monkeys can now count successfully to 8 using a conditional loop, thanks to the genetic algorithm generator. Next, I want to see if they can solve some new problems.
It’s often the first program you write when learning how to code, so let’s try the classic “Hello, World!” program.
Say Hello, Clyde!
There are multiple ways we could write something that could be considered a Hello World program using our simple instruction set so we’ll try a few different approaches.
The first attempt is to simply write the correct sequence of characters at memory address 0. This is similar to the number sequence Exercise, except that there’s no real algorithmic solution. There’s no source data to read from and no null termination, they just need to spit out the correct values in the sequence somehow.
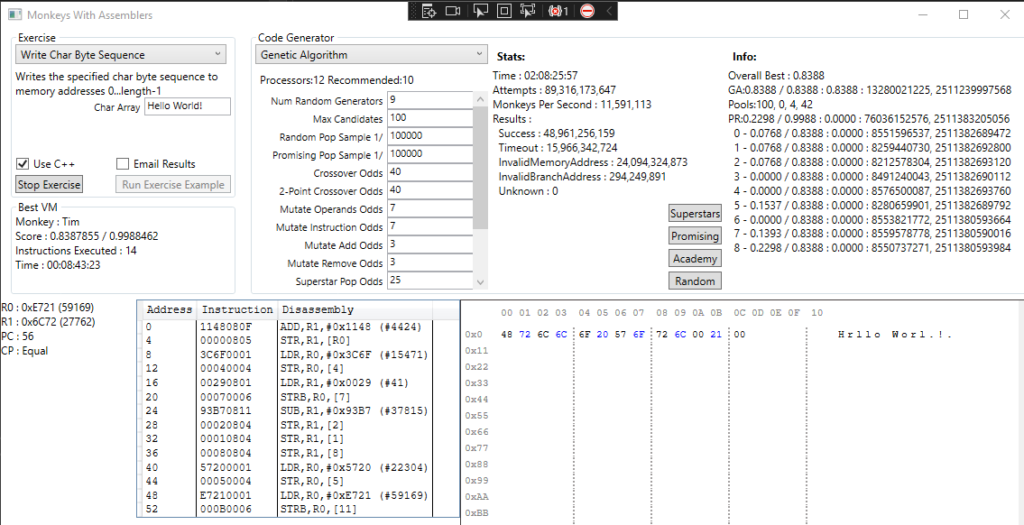
It kind of works, up to a point. Once we hit a certain score I’m seeing a couple of obvious things:
- We cannot create new random sequences that are good enough to enter the Academy or Promising populations, not within a sensible timeframe anyway. The chances of doing so are just ridiculously low.
- We’re expecting the monkeys to create this sequence out of thin air, but the vast majority of the time they’re just choosing complete unsuitable values, something that has always been an issue.
Trying to fix this led me down a long and winding path of underwhelming modifications…
Academy Entry Criteria
I tried to address the first issue by playing with the academy entry criteria (the multiplier we use when determining whether a solution’s score is good enough to enter the academy). Lowering it from 50% to 25% had a noticeable impact. It’s finding a valid but non-optimal solution in just a few minutes:
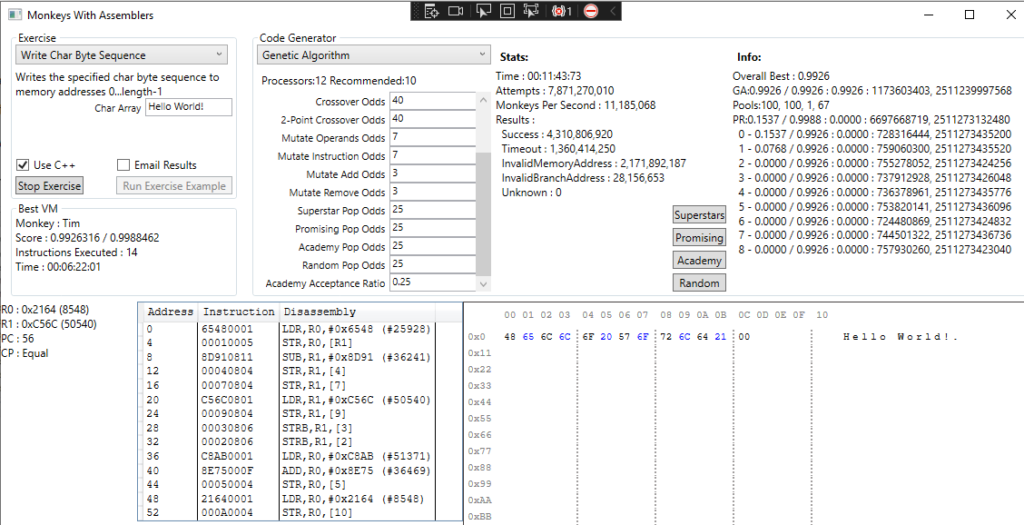
However, that value doesn’t work so well for other Exercises which are now getting overwhelmed by a low quality academy population, so we need something more flexible. What if we lower this percentage dynamically over time if there are no new admissions, essentially lowering the standards at the academy to attract more monkeys the longer the academy remains stagnant?

This helped. A bit. I really need better metrics to measure how effective changes are in general, but at least this appeared to fix the academy problem in the other Exercises. Overall this approach seems to help nudge the generator along at the mid-to-late stage when it’s struggling to find promising new solutions, but it’s not particularly useful beyond that.
Number Generator
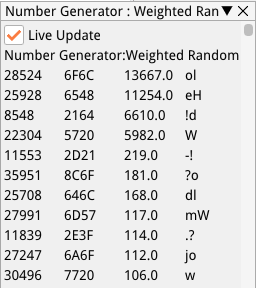
To try to improve the efficiency of the character sequence generation, I thought it would be interesting to add a weighted random number generator to produce numbers when choosing constant values in the code generators, instead of the current fully random generator. Each of the 65536 potential values has a weight which is modified each time it is used in a program that meets certain criteria. For now, this includes all Superstar and Academy programs, but also high-scoring Promising programs. For example, if a solution enters the Superstar pool which uses the value 0x6548 (“He”, in ascii), its weight will be increased (see image, below):
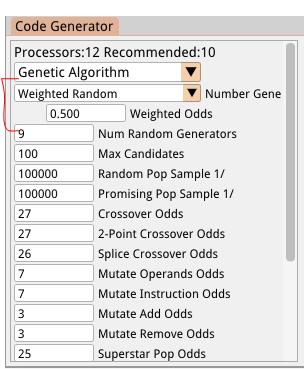
We also expose the odds of a weighted number being chosen instead of a purely random number, and allow the user to choose which type of number generator the code generator will use:
The first pass didn’t seem to have any significant impact. One issue is that we’re sharing the same number generator for all value-based instructions (Eg. LOAD, ADD and SUBTRACT) which limits how effective it can be. We should probably use a separate number generator for each instruction type. For example, we want to encourage the use of something like LDR R0, “He” when building a Hello World solution, which provides us with the first 2 correct characters in the sequence, but we don’t want to use SUB R0, “He”, which gives us a value that is probably useless. The same applies when choosing memory addresses for moving values or branching. Also, we might just be compounding the evolutionary-dead-end issue by weighting numbers like this.
There’s definitely something to build on here though, using more custom number generators in future, and for now it’s an interesting setting to experiment with.
More Multicore Monkeys
Like the original random code generator, the genetic algorithm code generator can also benefit from being executed on multiple cores.
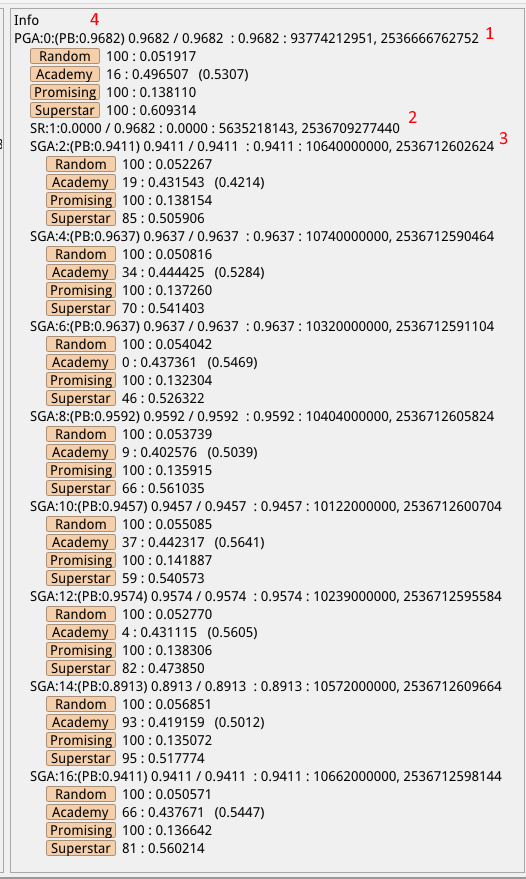
The setup is similar to the parallel random generator, with a parent parallel generator (1, in the image above) which spawns and manages multiple serial child generators (3), with a few exceptions:
- Unlike the random version, the parent in this case will generate code in addition to managing its child generators. This works in the same way as the serial version except that it will also populate itself with the Superstars from the child generators. It’s basically the same generator but it’s benefiting from the hard work carried out by the child generators and should lead to better results (see 4, where the parent has a personal best result which outperforms every single child because it was able to combine the successes or those multiple children).
- The chosen random number generator will be shared across the parent and all children. This allows the weighted version to have its weights affects by all generators and to share the values across them all. This could, indirectly, allow one generator to help nudge another generator out of an evolutionary dead-end (or, more likely, push them all down the same dead-end!).
- The parent generator will manage a single serial random code generator which will provide itself and all children with a continuous supply of random monkeys (2). Usually the Genetic Algorithm generator spawns its own random generator thread but most of those random solutions are just ignored because there are far too many of them to process in any useful way, thus wasting a lot of processing power. A single random generator will, for now, provide more than enough random monkeys to play with.
- We have the potential to give the parent generator much more power. For example, it could completely reset any child generators which it deems to be stuck in a dead-end. It could also initialise each child generator with a different set of parameters. For example, we could have one generator which is tailored for writing sequences, like our first Hello World example, and another which is more likely to produce loops. We could even detect which type of generator is producing better results and spawn more of those as we try to find an optimal solution.
Here it is in action, with 6 child generators:
On average it takes just under a minute to find a correct solution. It’s faster now and it’s not getting stuck without a solution, so I’m happy with the progress.
I made some other adjustments along the way, adding a new CROSSOVER_SPLICE operator and the concept of ‘extra mutations’ which allows two consecutive operators to be applied in sequence before evaluating the result. This seems to be common in genetic algorithms and can help in cases where we reach a dead end with a particular solution because two simultaneous changes must happen in order to improve its score.
Now, let’s try a different implementation of “Hello World!”.
Parrot Monkeys
The second Exercise will copy some static text from one part of memory and place it at another place in memory. This gives us some *slightly* more complex loop logic to test.
To support this we’ll add a new, simple read-only data section to our virtual machine. It’ll begin at address 0, the size will be determined by the Exercise configuration, and then regular RAM will follow that at an instruction-aligned address. Program memory will still remain separate for now, but it would make sense to merge it all into contiguous memory at some point.
The code generator will be aware of the location of RAM and pre-initialised ROM but won’t be given any clues as to what’s contained there.
Here’s the first attempt:
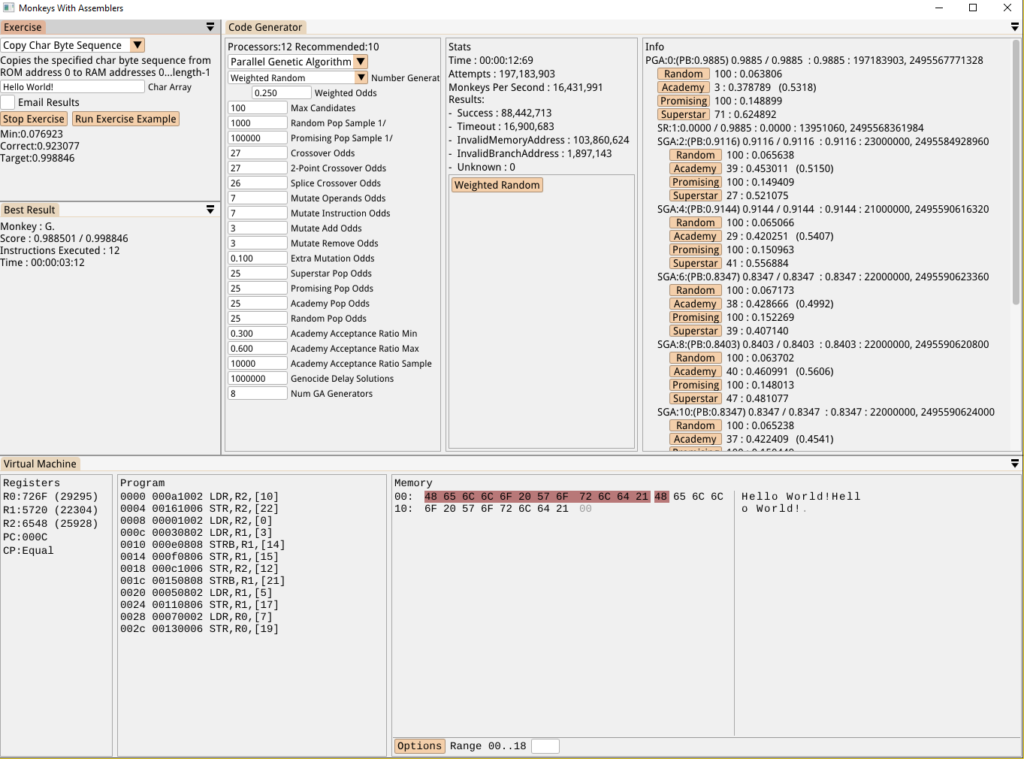
The area of memory highlighted in red is the new ROM section and we can see the RAM section afterwards where the destination text exists. Rather predictably, the first solution the monkeys found was a sloppy sequence of copies from ROM addresses to to RAM addresses instead of a loop.
I don’t have an immediate solution for this so I’ll just plough ahead with the other Exercises for now, the next one being almost identical to the one above but with the addition of a null terminator at the end of the string (ie. more suited to a string copy than a mem copy):
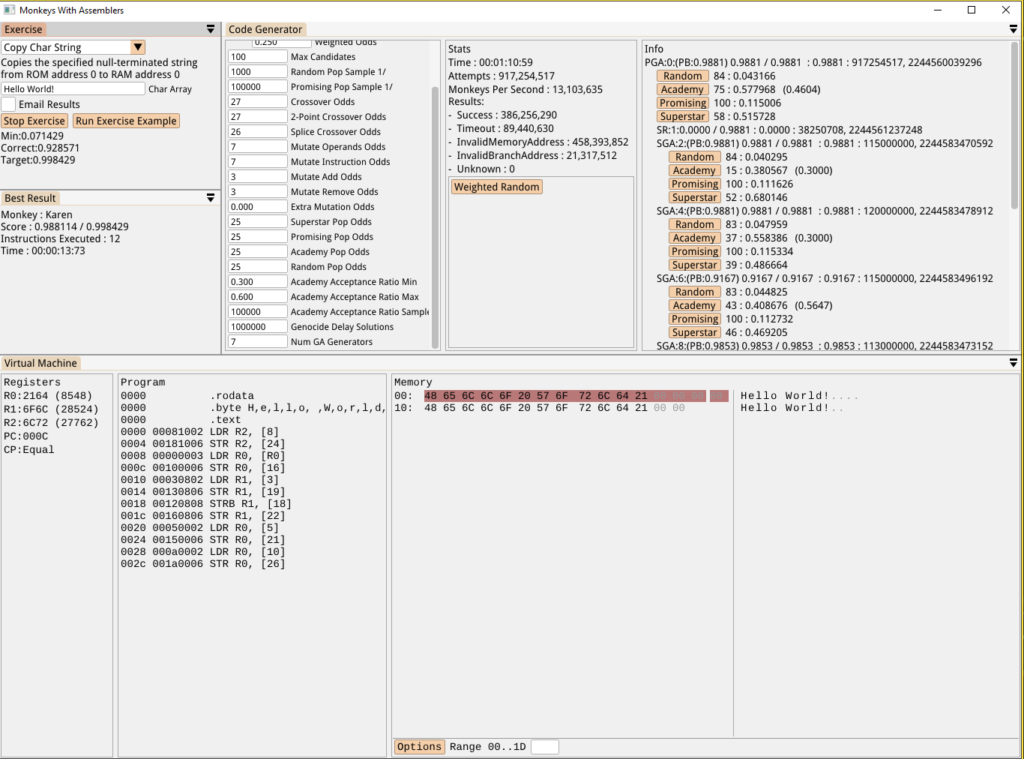
As expected, it just created a sequence of Load/Store instructions to brute force the copy and doesn’t seem to be finding the looping solution that could take advantage of the null terminator. There’s something I’ve wanted to add for a while which might help to improve that…
Multiple Tests-per-Exercise
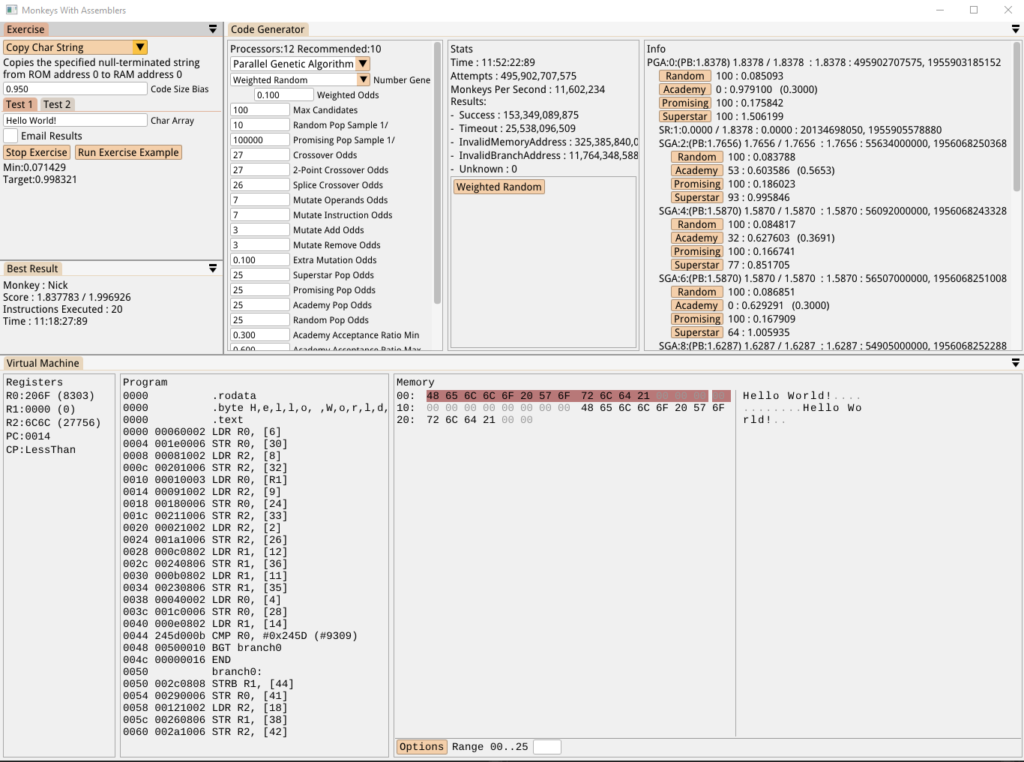
The solution the monkeys created above works efficiently for strings of exactly 12 characters, but what if we want code that can handle strings of different lengths? I figured we could just add multiple sets of input data for these types of Exercise, and then test the solutions against all input sets in order to determine an overall score. So now we have our original “Hello World!” test set and a second “Bonjour Tout le Monde!” set (oui, les singes parlent francais!):
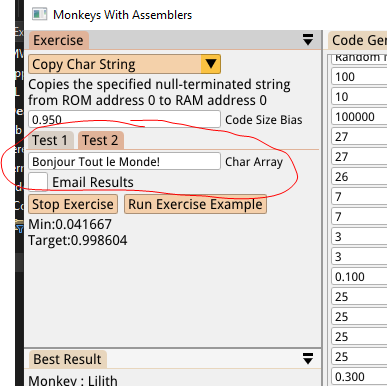
My thinking here is that while the brute force sequence approach will work up to a point, the score will taper off once the first 12 characters are written. Trying to write 13+ characters in the first Test will trash memory and result in an error, and failing to write 13+ characters in the second Test will prevent the score from improving at all since our scoring algorithm is skewed heavily towards reaching a ‘complete’ solution.
In that case *surely* the genetic algorithm will favour the looping solution. Riiiggght????
Well, not quite. It still quickly hones in on a sequence of Load/Stores in order to copy the first 12 characters, and then eventually produces the nasty hack below. This copies the first part of the string and then adds a condition which is able to determine which string we’re dealing with and, if it’s the longer Test string, copies a few extra bytes at the end. Hilariously messy stuff:
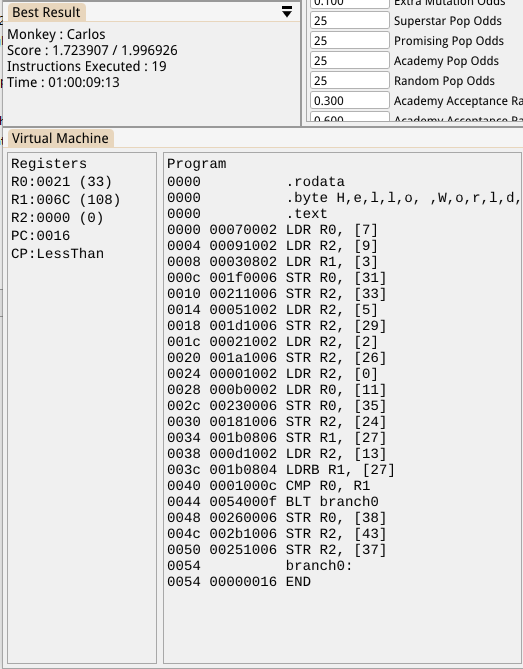
I wanted to verify that the code is even capable of generating a loop for this case though, so I tweaked the code generator so that it only ever uses constant numbers below 25 (which reduces the number of garbage solutions exponentially) and it managed to produce the solution below. This actually loops, copying 2 bytes at a time, and terminates when it reaches the end. It’s a bit messy, it assumes an even number of characters and would break if values above a certain value were stored in the byte following the string (I think), but that can be fixed by modifying the Exercise test data and evaluator to make it more robust:
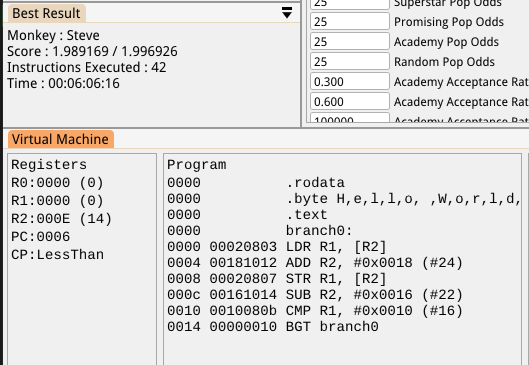
So, I’m calling this a failure for now. I have big improvements to the code generation planned which I think will fix this, so it can wait. It’s actually fun going back to older Exercises after making improvements to see how they’re now faring anyway.
Logging Monkeys
The last Exercise is to log the “Hello, World!” text to some sort of console.
To accomplish this we’ll add basic console support to the VM. I looked around for examples of Hello World in ARM and found this tutorial which uses the concept of a SYS_WRITE system call. It looks like a reasonable approach to take so we’ll loosely follow that.
In order to do this I added a new “SVC” instruction which makes a system call that requires specific registers to be set up as follows:
R0 = 1 : use the stdout file descriptor
R1 = 0 : Address of the data to write (the beginning of our ROM)
R2 = X : Length of the data to write (our string length)
R7 = 4 : This is a common representation of the SYS_WRITE system call
When the SVC call happens the VM reacts to the above settings by pushing the specified output to its console buffer, then our Exercise scores the results using that output instead of the RAM area we’ve been using until now. Here’s the first attempt:
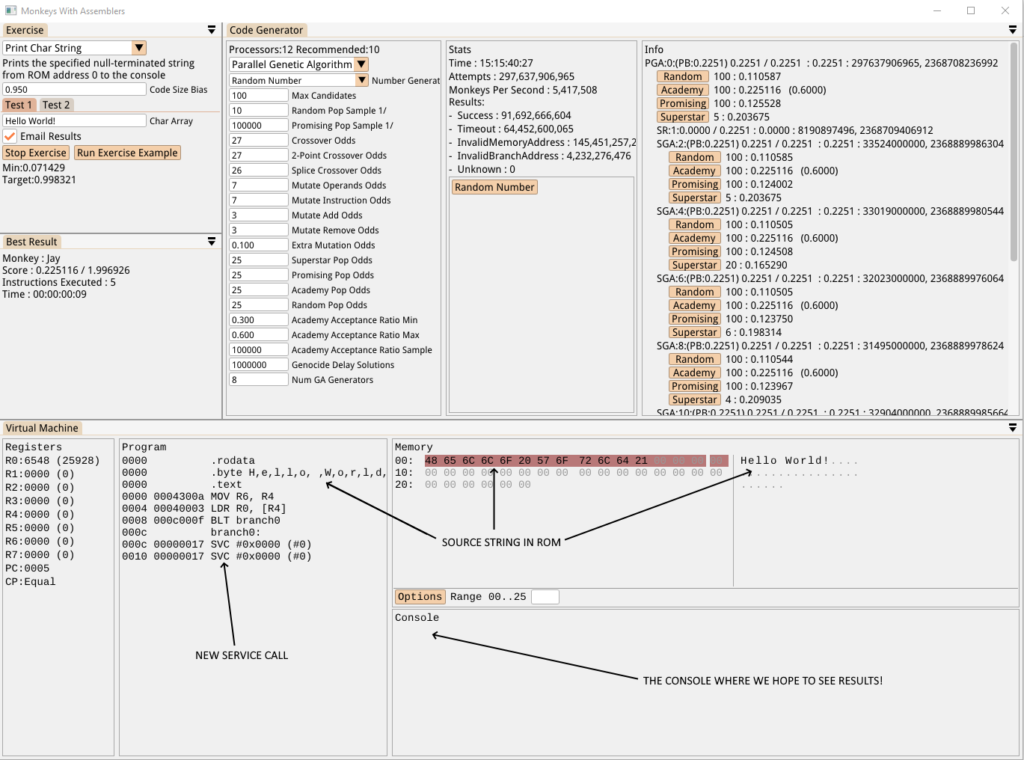
After 15 hours, nothing. The issue here is that the monkeys need to set up a very specific set of registers with specific values and then make the system call using another specific value operand. Until *all* of those criteria are met then *nothing* will be written to the console so the score we see above cannot be increased. The above solution was only considered at all because it was the first to use 5 instructions, which is the minimum number of instructions allowed for this Exercise.
To verify that a solution is even possible, as we did on the previous exercise, I limited the choice of operand values to 0-31:
Well, that worked, we have a working solution in approximately 10 seconds. It’s not a great solution, it doesn’t actually consider the length of the strings, but it’s still 100% valid based on the testing criteria (for both test sets it copies the required ROM section to console without any VM execution errors).
Relying on manual hacks isn’t good enough though. I give the monkeys a fail on this one.
*slowly eats pile of bananas*
They Made A Monkey Out Of Me!
I think we finally reached a point where the existing combination of the random and genetic algorithm code generators has met its match.
That said, with the right tweaks to the number generator and exercise validation I’m pretty certain we could solve the dead-ends we ran into above.
So Is It Time To Quit And Get A Real Job Yet?
Oh my goodness, no! The biggest limitation we have now is that the monkeys are churning out almost entirely random code. The vast majority of it is nonsense. The next step is to replace, or at least supplement, the serial code generator by teaching them to write something that at least vaguely resembles real code. For that we’re going to need a language that’s based on a real machine, so I need to go away and figure out what that machine would be. ’til next time!
A genuinely good read; keep ’em coming!