Now we have a system that can run code and examine the results of that execution, but I’m still concerned that this whole concept could fall at the first hurdle, so it’s time to test out the code generation.
First Exercise – Write non-zero byte at address 0
I added the concept of an Exercise, which defines the initial state of a virtual machine, some code generation parameters and a scoring system to measure the results of a program that runs on that VM. The heuristics of the scoring will vary, but for this first Exercise we simply score 1 if the byte ‘1’ is written at address 0, otherwise zero. Success or failure.
Randomly Generating Code
I chose a very basic approach to code generation, which is:
- Randomly choose an opcode
- Randomly choose a valid register for it to operate on, if applicable
- Randomly choose a valid operand for it to work with, if applicable. Either another register, a 16 bit value or a 16 bit memory address
- Create an instruction from this and add it to a program
- Repeat X times. For our first test we’ll create programs between 2 and 5 instructions long.
Then we run that program, evaluate the results and repeat until we hit our desired score, in this case 1.
Surprisingly, it works!
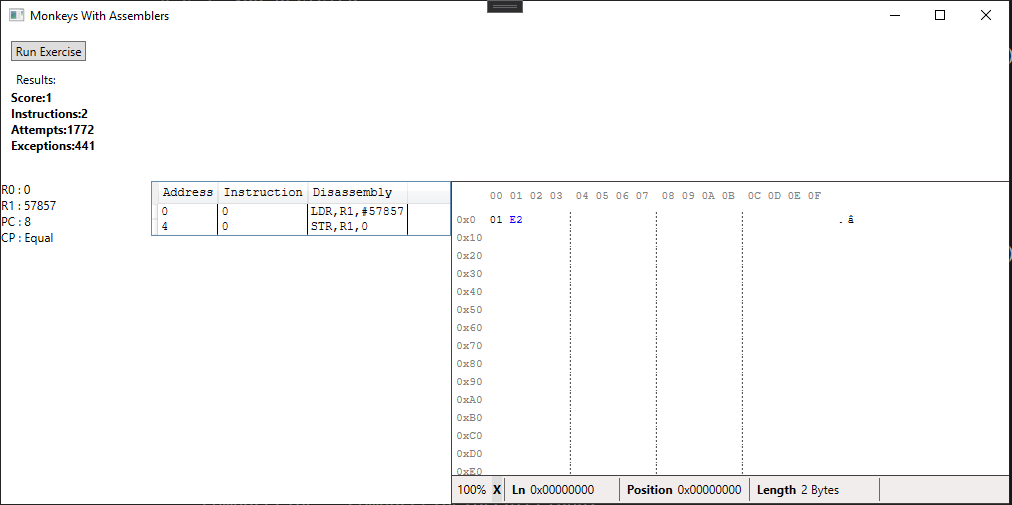
It created a valid program by randomly sequencing instructions, it met the criteria of placing a value of 1 at memory address 0 and it only took 1772 attempts to find a valid solution.
The 441 exceptions are all the result of the dreaded infinite loop, some as stupid as this:

We detect these infinite loops by specifying the maximum number of instructions that can be executed for a given exercise and having the VM exit with an error if we reach that limit. We can avoid the worst case above by simply not creating instructions that branch to their own address, or even the previous address since there aren’t any single, preceding instructions that can modify the state of the system and change the outcome of a branch.
Quirks aside, it was reassuring to see the different programs that the monkeys created, all of them basically achieving the same result even if some of them are a bit ridiculous:
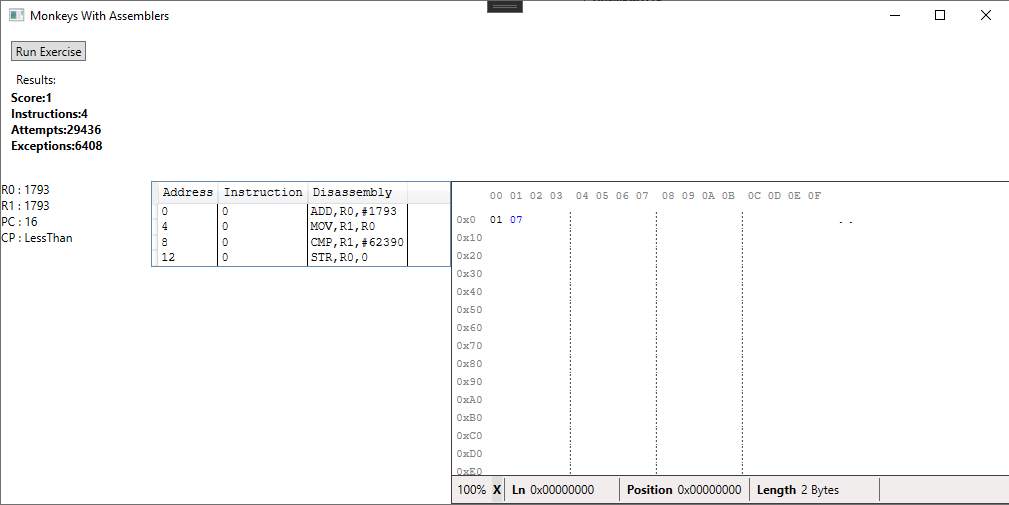
The useless instructions like the CMP above are something we’ll address in the next exercise.
When calculating the score for program we ignore the value at address 1, which explains why this currently works by writing any 16 bit value containing a 1 in the least significant byte. I added ‘load/store byte’ opcodes to allow for potentially cleaner or more efficient solutions in future:
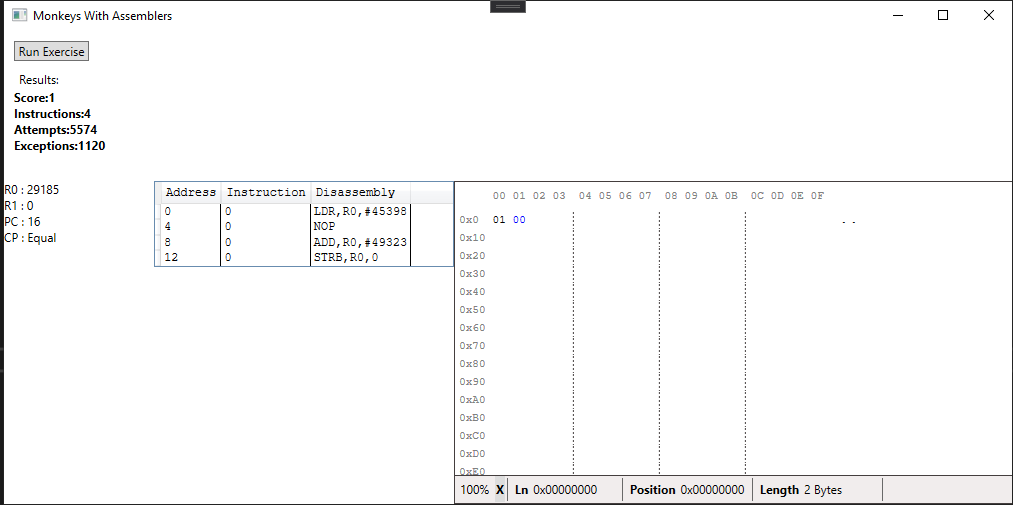
You have to admire that completely pointless NOP though.
Exercise 2 – Create a sequence of numbers
Let’s create a more complex exercise which places a sequence of X numbers in memory, starting from address 0. We’ll start with just a 1,2,3 sequence which lets us test whether our monkeys can create a loop. In theory, they will, but will it happen in a reasonable amount of time?
I made a few improvements before the first attempt:
- Added a new STORE instruction which stores the contents of a register into the address stored in another register, to allow us to iterate through memory effectively.
- Moved processing to a BackgroundWorker, a quick and simple way to free up the UI.
- Repeat code generation until a ‘target score’ is reached. Still 1 in this case.
- Track the best score so far and display the VM state for the program that achieved that score. This allows us to track the progress to some extent.
- Track different types of exceptions. Now we have infinite loops and the ability to write to invalid memory addresses.
- Add some logic to reject ‘invalid’ randomly generated instructions. These include:
- Branching to its own or its previous address (the pointless infinite loop mentioned earlier).
- Moving a register into itself. We don’t modify any flags on the move so it’s pointless.
- Adding or subtracting 0 to/from a register. See above. Maybe we’ll undo this if we add expand our use of condition flags in future.
Here’s the example program. We’ll limit the program size to 7 instructions since that should be enough to either create a working loop or to just fill the memory using a sequence of stores:
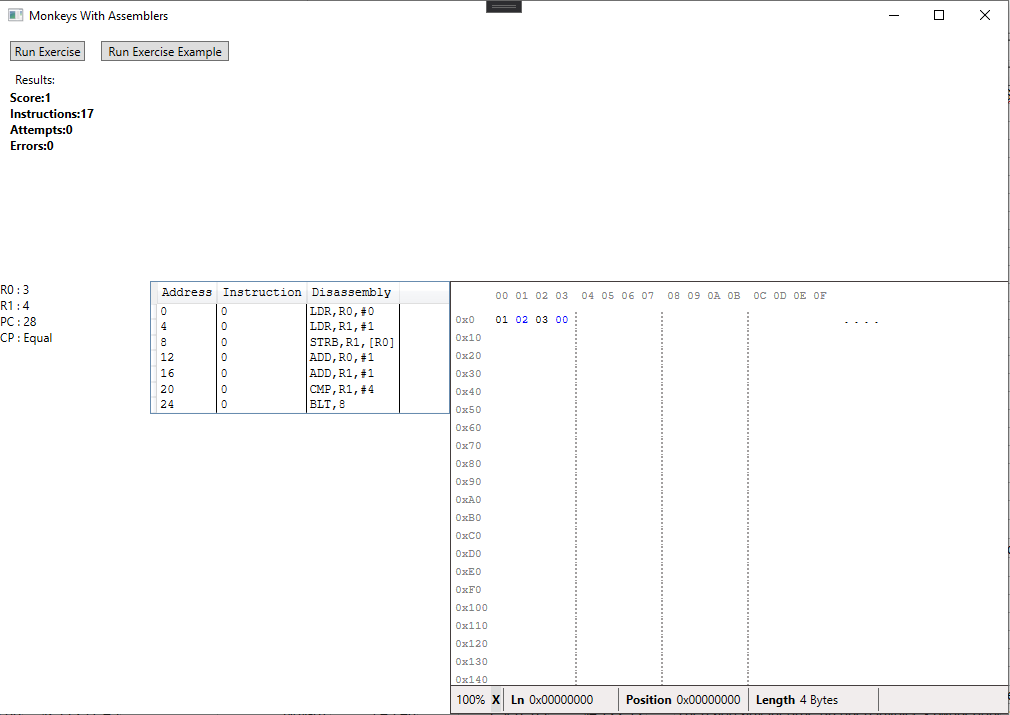
And here is the monkeys’ first attempt:
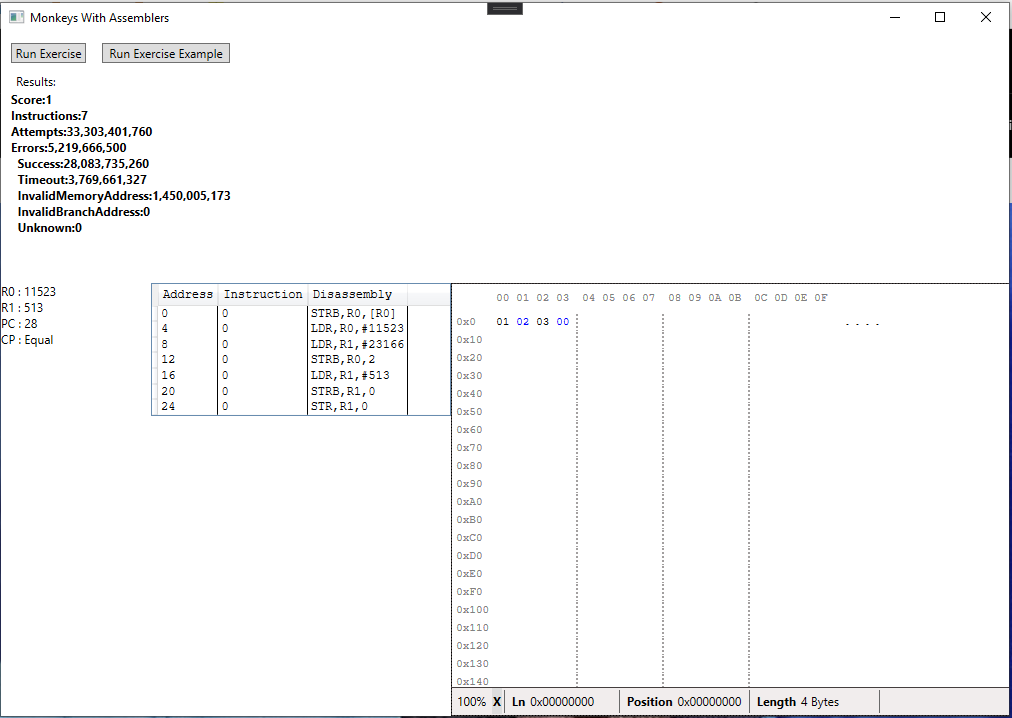
It took a mere 33 billion attempts to create something that worked, which took about 12 hours. It’s quite ridiculous but not entirely surprising. Some observations:
- The solution is still nonsense.
- We need to include execution time in the scoring heuristics so that we can advance past this solution and keep searching for a more efficient one. For such a short sequence this would probably be a combination of 4 LDR/STR instructions instead of a loop.
- An exercise should specify a Min and Max number of instructions to include in a program. In this test were generating programs of 1-3 instructions which couldn’t possibly solve the problem using the available instruction set.
- 12 hours is impractical to solve such a simple problem, we’ll need to do some optimisations.
Before delving into the optimisation phase, though, I want to give the monkeys one more chance with some minor changes:
- Include the execution time when calculating the program score, as mentioned above. We’ll assign the score as follows:
- 25% for each correctly placed number in the sequence (for a total of 75%)
- 20% based on the number of instructions executed
- 5% based on the program length.
- That way we favour correct placement of numbers over execution time but will still continue towards a more optimal solution once we’ve created a valid sequence.
- Specify the minimum number of instructions
- Specify which subset of instructions can be added after each opcode. For example, a conditional branch should only be added after an instruction which sets the conditional flag (the COMPARE instructions) and the first instruction should never be an END instruction. We’ll remove the NOP while we’re at it. This is not to give the monkeys knowledge on how to write good code, it’s merely to prevent completely useless or destructive instructions which only serve to increase the processing time.
- Add a StopWatch so that we can track the execution time and calculate the number of attempts per second. This will provide a basic benchmark for profiling.
- Add an option to choose the current exercise, which is handy for testing!
- Give names to our monkeys. It’s the only request I’ve had so far and it seems rude not to. I exported my Facebook friend list and the result is, frankly, a bit disturbing.
- Run in Release! The tests so far have been running in a Debug build.
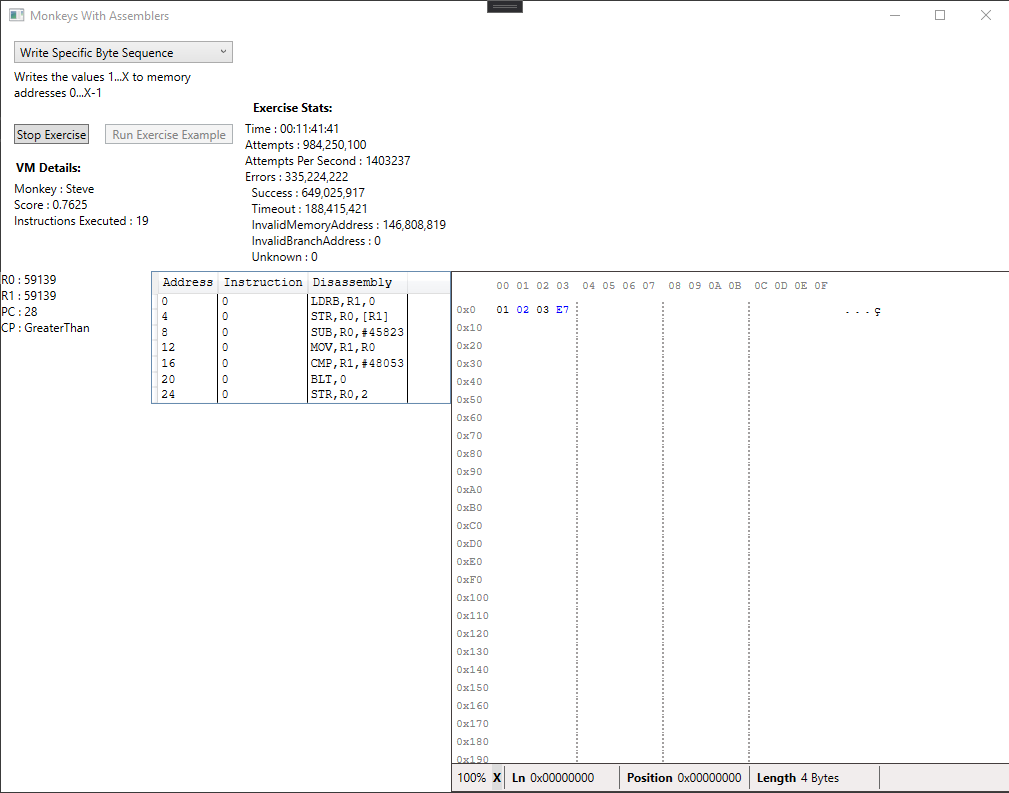
With all of those changes, here it is in action. We run the byte-sequence exercise and observe some of the first results the monkeys create as the system slowly creeps towards a better solution:
We average somewhere around 1.6 million programs per second on a single core in Release. That’s a lot, it actually feels like a pretty crazy number, but clearly we need to scale that up if we’re going to solve even basic problems in a reasonable amount of time.
With these changes we were able to find a solution in less than a billion attempts, much better than the original 33:
And if we let it run to its conclusion we get the following result. It’s still 36 billion attempts but it produces the smallest program with the lowest execution time so far:
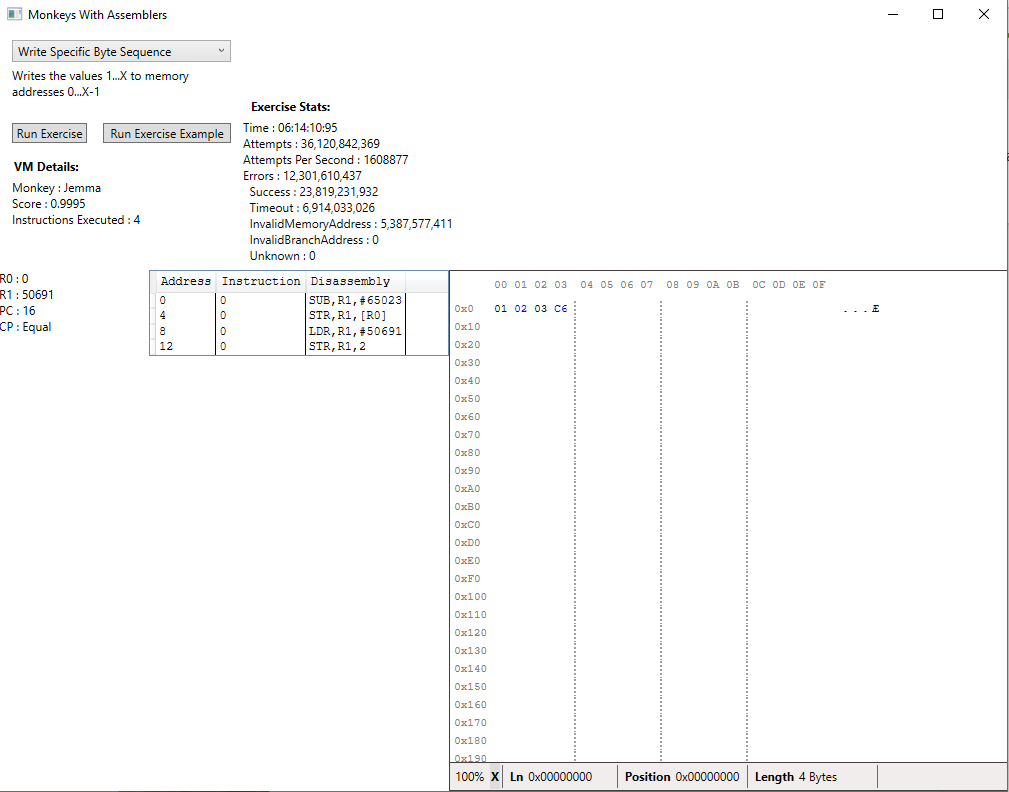
I’m a little disappointed at how poorly the system handles anything remotely complex, but mostly I’m relieved that it works at all!
What Next?
I have some ideas for future Exercises but I don’t want to wait days to see the results, so it’s time for some serious optimisation. Let’s see what these monkeys can really do!
This is pretty awesome stuff! Keep it up!!